Results
Original Dataset Evaluation
Accuracy Score: 75%
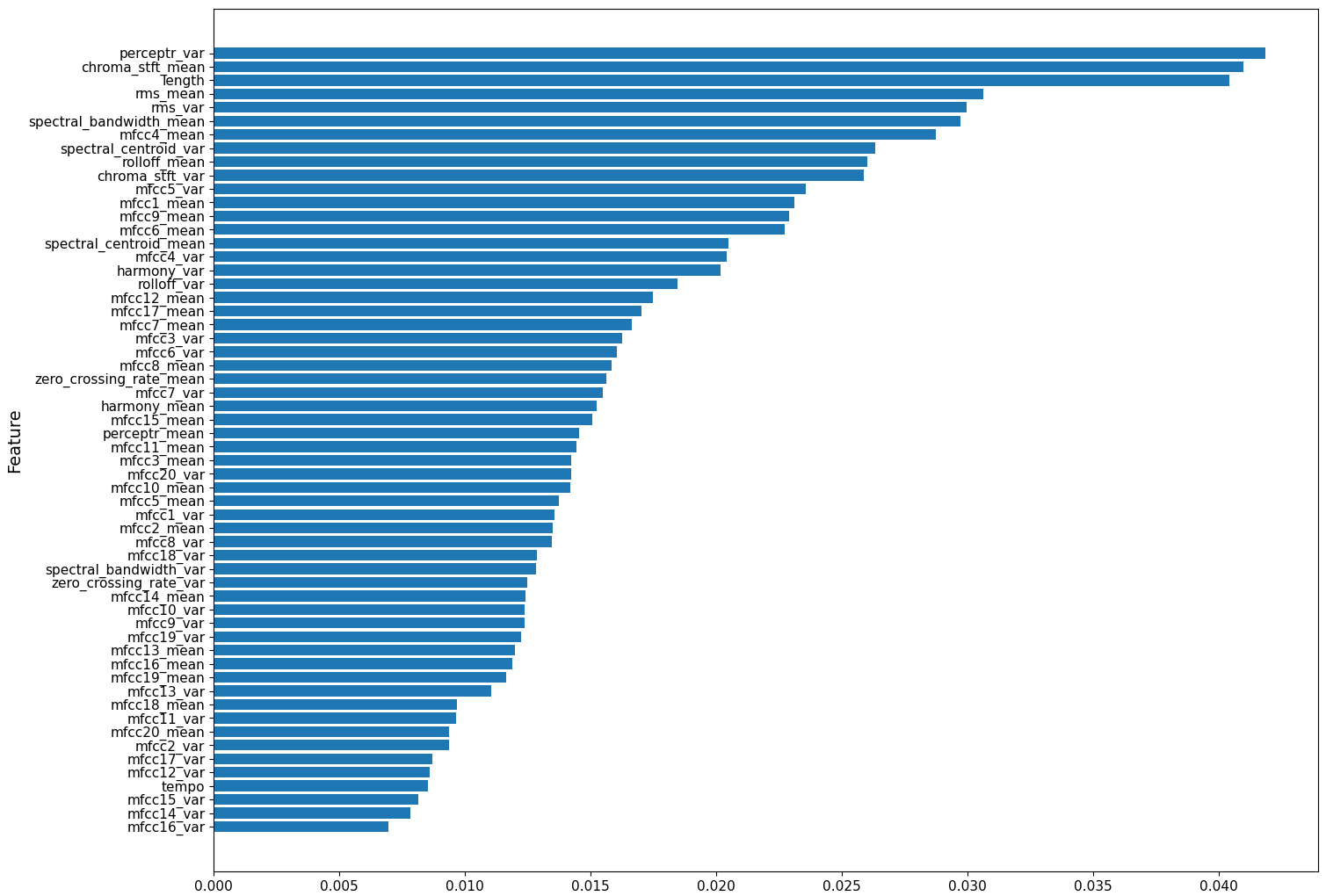
Feature Importance
Confusion Matrix
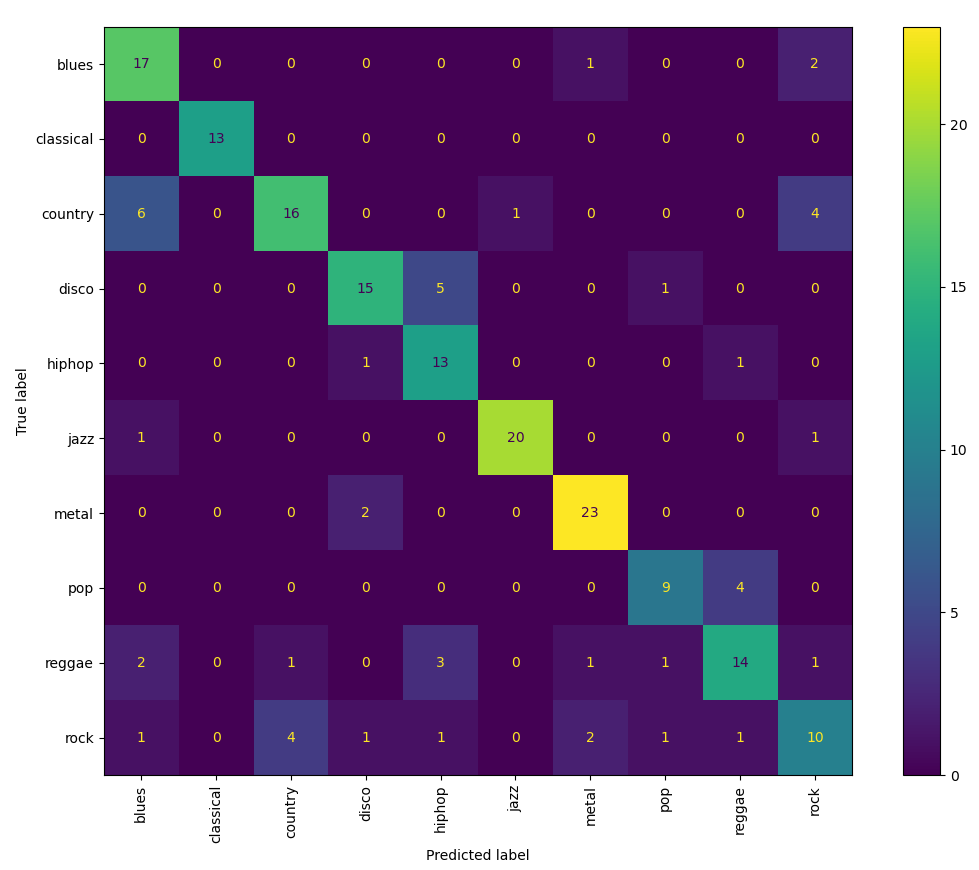
The random forest model trained on the original dataset had an accuracy of 75%. The confusion matrix shows that several genres, such as classical and jazz, are classified with relatively high accuracy, whereas genres like pop and rock show more frequent misclassifications The model is better at distinguishing between certain genres than others, potentially due to similar acoustic features that genres share, making it more difficult to differentiate between them. For example, classical music has a 100% classification rate, potentially due to its unique lack of percussive instrumentation. On the other hand, rock had the worst accuracy (10/21, or 48%), often misidentified as country or metal. Additionally, as this was trained on the full dataset, it may also be the effect of duplicate files in the training and testing sets, meaning the model may have overfitted to these repeated samples.
The feature importance graph shows that perceptual variance, chroma stft mean, and ms mean were among some of the most important features, showcasing that harmonic and melodic characteristics were integral in differentiation.
Modified Dataset Evaluation
Accuracy Score: 78.42%
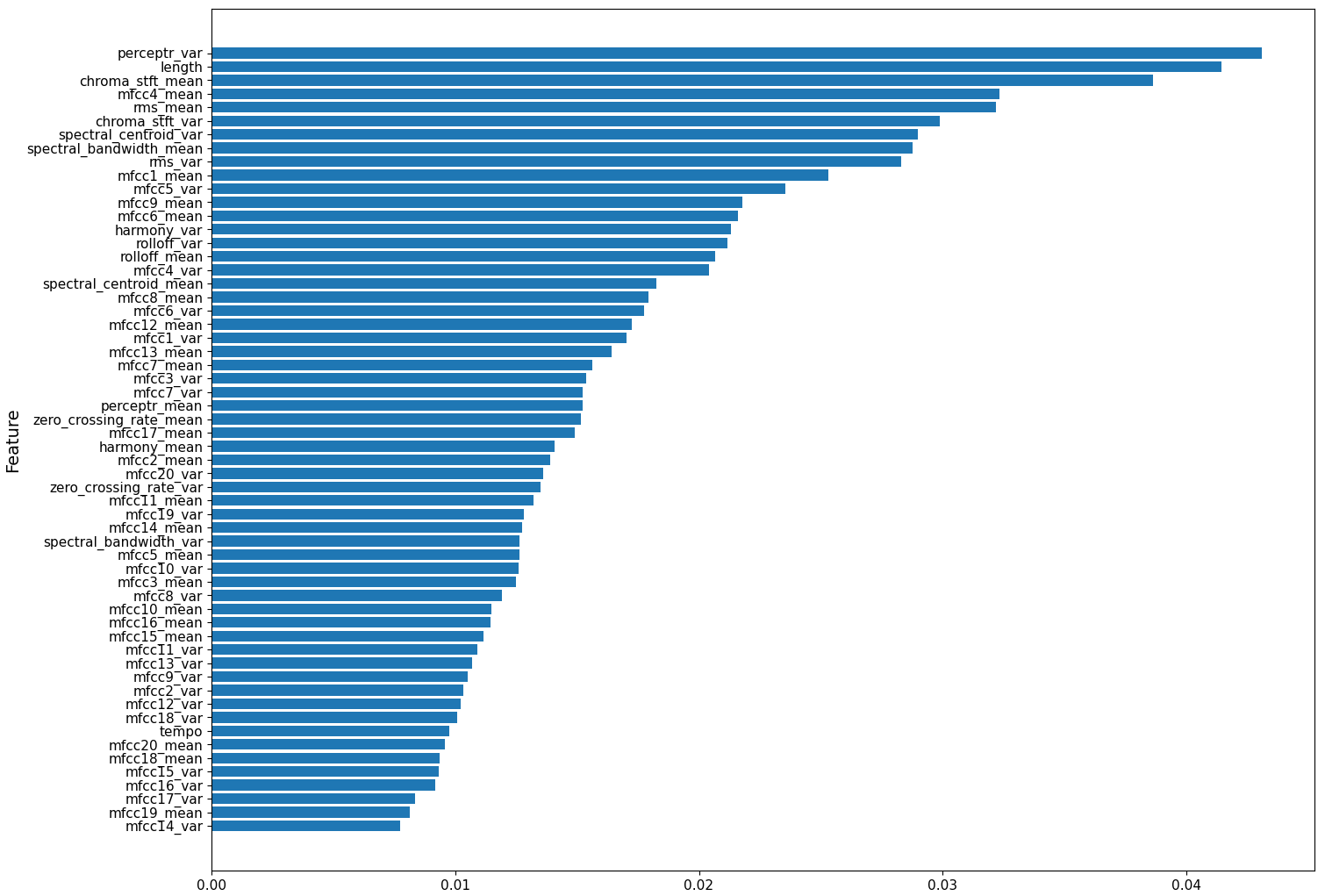
Feature Importance
Confusion Matrix
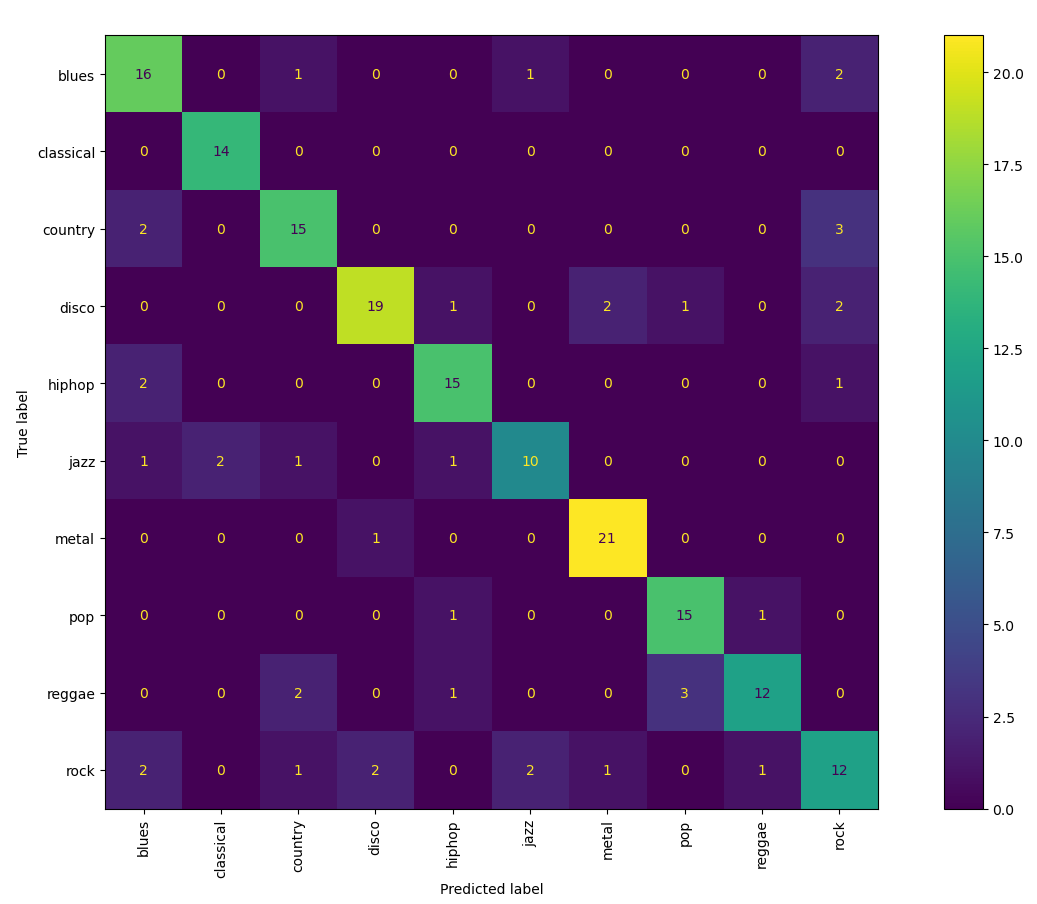
The random forest model trained on the modified dataset improved accuracy from 75% to 78.42%. The confusion matrix shows that the model improved significantly at classifying pop (after 9 files were removed), and slightly improved with classical, blues, and country (all of which were not duplicated genres). On the other hand, it shows that jazz accuracy decreased significantly (from 91% to 45%), with 13 duplicates removed, and reggae decreased slightly, with 11 duplicates removed. This suggests that the model was incorrectly inflating the accuracy of jazz and reggae by overfitting to the duplicated audio files, and after removal, the model is able to better predict other genres. The feature importance graph shows that perceptual variance, chroma stft mean, and ms mean were still among some of the most important features.